

Every cloud environment has two versions of itself. There is the version defined that exists in version control, reviewed and approved. And there is the version actually running in production right now, which has been touched by console clicks, emergency hotfixes, automated scripts, and changes nobody wrote down.
These two versions are rarely identical. The gap between them is configuration drift, and it is one of the most underestimated risks in cloud security. Not because it is exotic or hard to understand, but because it is invisible by default. A security group rule added manually during an incident at 2 AM. An S3 bucket policy loosened temporarily for a debugging session and never tightened back. An IAM permission granted directly in the console because the Terraform PR would have taken too long to merge. None of these are malicious. All of them are drift. And drift is how secure infrastructure becomes insecure infrastructure without anyone deciding to make it that way.
This article covers what configuration drift actually is and why it happens even in well-run engineering organizations, the specific ways drift creates security and compliance exposure, the methods available for detecting it. From manual audits to continuous monitoring, and what effective drift management looks like in 2026. It closes with a practical look at how Cloudanix approaches continuous drift detection and remediation across multi-cloud environments.
Written for cloud architects, DevSecOps leads, and security engineers who are responsible for keeping production infrastructure aligned with its intended, reviewed, and approved state; and who know from experience that this is harder than it sounds.
Configuration drift isn’t a one-time event you fix and move past. It is a continuous process that starts the moment your infrastructure goes live and never stops. Which means detection has to be continuous too, or it isn’t really detection at all.
What Configuration Drift Actually Is
Configuration drift is the divergence between the intended state of your infrastructure, as defined in your Infrastructure as Code, your security policies, your architecture diagrams, and its actual, running state in production. The term originates from traditional IT operations, where server configurations would gradually diverge from their baseline image through ad hoc patches and manual changes. In cloud environments, the same phenomenon happens faster and at far greater scale, because cloud infrastructure is provisioned, modified, and torn down through dozens of different interfaces simultaneously: the console, the CLI, automation scripts, third-party tools, and IaC pipelines, all touching the same resources.
Drift is not inherently malicious, and it is not always a mistake. Sometimes it is a deliberate, justified emergency change made under pressure. Sometimes it is a well-intentioned manual fix that nobody remembered to backport into the IaC source of truth. Sometimes it is a permission granted temporarily for a one-off task that was never revoked. What makes drift dangerous is not the individual change. It is the accumulation of unreviewed, unreconciled changes over time, each one moving the actual environment further from the state your security team believes it is securing.
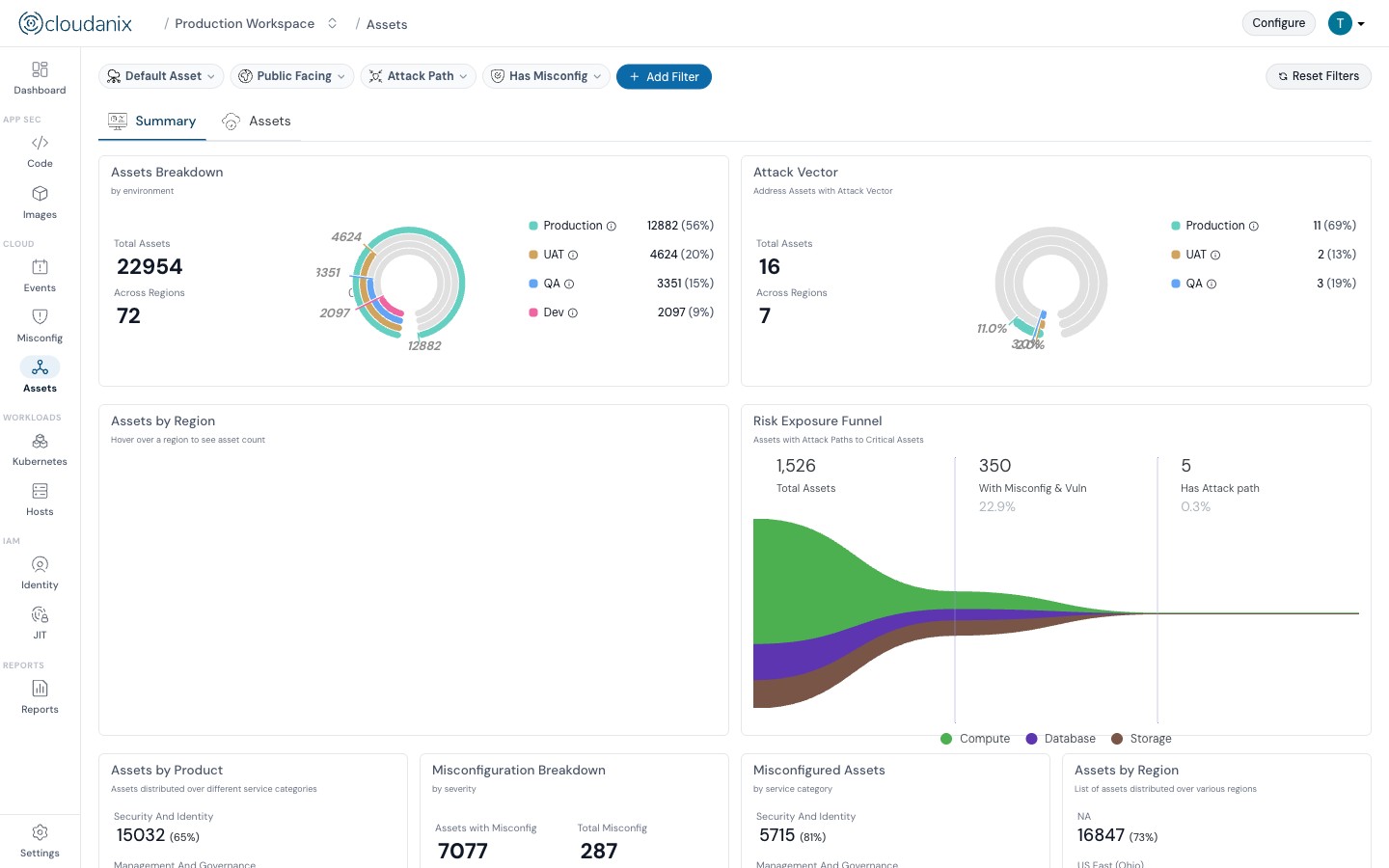
Cloudanix continuously detects configuration drift across AWS, Azure, and GCP — surfacing what changed, who changed it, and when.
Drift vs. Misconfiguration: A Useful Distinction
These terms are often used interchangeably, but the distinction matters operationally. A misconfiguration is a state that violates a security policy or best practice — a publicly accessible storage bucket, an overly permissive IAM role, or an unencrypted database. Drift is the process by which a previously compliant resource becomes a misconfigured one, or by which your actual infrastructure diverges from what your IaC declares it should be. Every drift event has the potential to become a misconfiguration, but not every misconfiguration originates from drift. Some are present from the moment a resource is first created. Effective cloud security programs need to address both: catching misconfigurations regardless of origin, and specifically tracking drift so you can identify where and why your control gaps are forming.
Why Drift Happens Even in Well-Run Organizations
Drift is not a sign of a poorly managed cloud environment. It is the natural result of how cloud infrastructure actually gets operated: by multiple people, multiple tools, and multiple processes, often under time pressure. Understanding the specific sources of drift is the first step to managing it.
1. Manual Console Changes During Incidents
When production is down, engineers fix it the fastest way possible: often through the console, not through a pull request. A security group rule opened to resolve connectivity, an instance resized to handle load, a permission granted to unblock a deployment. These changes are usually correct in the moment and almost never backported into IaC afterward.
2. Multiple Teams Touching the Same Infrastructure
In any organization beyond a handful of engineers, more than one team or individual has write access to the same cloud account. A platform team manages the IaC pipeline; a security team adjusts IAM policies directly for an audit; a data team spins up a temporary resource for an analysis project. Without a single enforced path for changes, drift is the default outcome, not the exception.
3. Out-of-Band Automation and Scripts
CI/CD pipelines, internal automation scripts, and third-party SaaS integrations frequently modify cloud resources directly through APIs that are outside of the IaC workflow entirely. A monitoring tool that auto-tags resources, a cost-optimization script that resizes instances, an internal tool that rotates credentials; each is a legitimate automated process that creates a state IaC does not know about.
4. IaC Coverage Gaps
Most organizations did not start with 100% of their infrastructure under IaC management. Legacy resources, resources created before the IaC pipeline existed, and resources provisioned by acquired teams or projects often sit entirely outside the version-controlled source of truth. Meaning there is no baseline to drift away from in the first place, and no way to detect divergence using IaC-based comparison alone.
5. Provider-Side and Default Behavior Changes
Cloud providers occasionally change default behaviors, deprecate configurations, or auto-apply updates to managed services. Changes that originate from the provider, not from your team, but that still move your actual infrastructure state away from what your IaC declares.
Why Configuration Drift Is a Security Problem, Not Just an Operational One
It is tempting to treat drift as a hygiene issue — something that makes infrastructure management messier but does not pose a direct security risk. This framing is incorrect, and the gap between the two becomes obvious the moment you look at how real incidents actually unfold.
Drift Is How Secure Baselines Quietly Become Insecure
An environment that passed its last security review with a clean bill of health is not necessarily the same environment running today. If your security posture was assessed against the IaC-defined state or against a point-in-time scan three months ago, and drift has occurred since, your actual risk exposure may be significantly higher than your last assessment suggested. This is precisely how organizations end up surprised by findings during an incident response: the compromised resource had a configuration nobody remembered approving, because nobody had.
Drift Defeats Policy as Code
Many organizations invest in Policy as Code, using tools like Kyverno, OPA, or Sentinel to enforce security and compliance rules at the IaC layer, before deployment. This is valuable and necessary. But Policy as Code only governs what passes through the IaC pipeline. A change made directly in the console bypasses that enforcement entirely. Drift is the blind spot that Policy as Code, by itself, cannot see. Which is why drift detection and Policy as Code need to operate together, not as substitutes for one another.
Compliance Frameworks Assume Continuous, Not Point-in-Time, Control
SOC 2, ISO 27001:2022, PCI-DSS, and similar frameworks increasingly expect evidence of continuous monitoring, not annual snapshots. A quarterly audit that confirms your S3 buckets were correctly configured at the time of the audit says nothing about the six weeks of drift that may have occurred since. Auditors are becoming more specific about this distinction and a security program that cannot demonstrate continuous posture monitoring is increasingly viewed as a finding in itself, regardless of what the snapshot showed.
Drift Multiplies in Multi-Cloud Environments
Organizations running AWS, Azure, and GCP simultaneously face drift on three separate planes, often with three separate teams, three separate IaC toolchains, and three separate native monitoring consoles. A security team watching AWS Config closely may have zero visibility into drift occurring in their GCP environment at the same time. Multi-cloud does not just add drift risk, it fragments the visibility needed to catch it.
A single drift event is rarely catastrophic on its own. The risk compounds when drift accumulates unreviewed over months; each small, individually reasonable change stacking on the last, until the actual environment bears little resemblance to the one your last security review approved.
How Drift Detection Actually Works And Where Each Method Falls Short?
Not all drift detection approaches are equivalent, and the differences matter significantly for how much risk exposure your organization actually carries between detection cycles.
| Approach | How It Works | Where It Falls Short |
|---|---|---|
| Manual Periodic Audits | Engineers manually compare console state to IaC definitions on a schedule | Slow, error-prone, and stale the moment it’s complete — drift happens continuously, audits happen quarterly |
| IaC-Only State Comparison | Terraform/CloudFormation plan diffs flag changes vs. the last applied state | Only catches drift if someone runs a plan — silent between runs, and blind to changes made outside IaC entirely |
| Native Cloud Config Rules | AWS Config, Azure Policy, GCP Org Policy flag rule violations within a single cloud | Single-cloud only, limited rule libraries, no cross-resource context, no remediation guidance |
| Continuous CNAPP Monitoring | Real-time event-driven detection across all clouds, correlated with identity, network, and posture context | Requires a platform built for continuous ingestion and graph-based correlation. Not all CSPMs do this well |
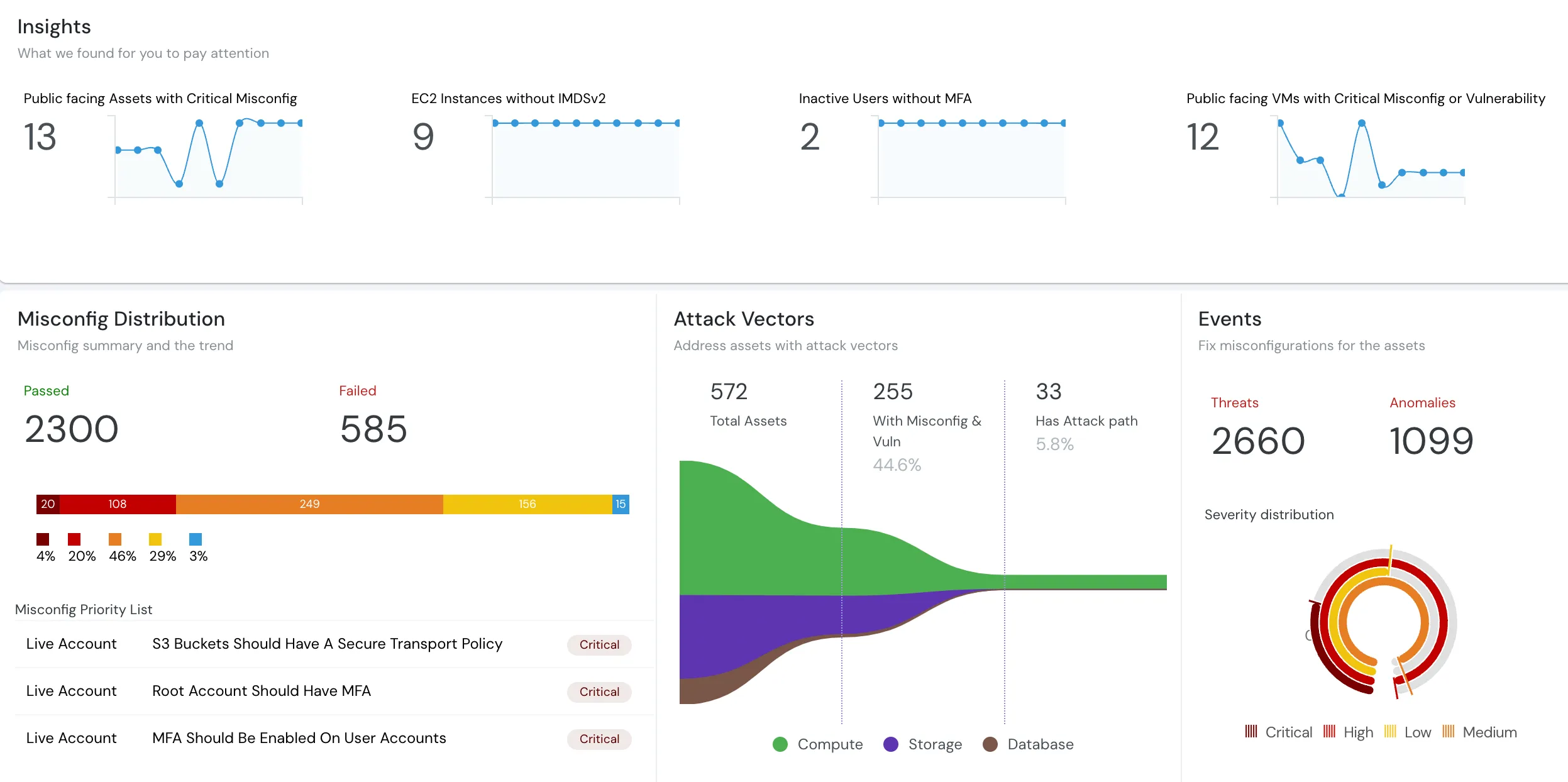
A continuous CSPM platform evaluates drift against 1,000+ rules with full cross-cloud parity — replacing fragmented, single-cloud approaches.
The throughline across the first three approaches is the same limitation: they are either periodic, single-cloud, or dependent on someone actively running a check. Drift does not wait for your next scheduled audit or your next Terraform plan. It happens continuously, in real time, across every cloud account your organization operates. Which means meaningful drift management requires detection that is also continuous, event-driven, and unified across clouds.
What Effective Drift Management Requires in 2026
Based on how drift actually originates and the gaps in traditional detection approaches, six requirements define what a mature drift management capability needs to deliver.
1. Continuous, Event-Driven Detection
Drift detection needs to operate on real-time cloud events (CloudTrail, Azure Activity Logs, GCP Audit Logs) not on scheduled scans. A change made at 2 AM should be visible before the next business day, not at the next quarterly review.
2. Multi-Cloud Unified Visibility
If your organization runs AWS, Azure, and GCP, drift detection needs to operate across all three from a single platform, not three separate native tools that each require a different login and produce findings in a different format.
3. Context, Not Just a Diff
Knowing that a resource changed is the starting point, not the answer. Effective drift management needs to show what changed, who changed it, when, and critically what else in the environment that change touches: is the modified resource adjacent to a sensitive database, does the new permission create a privilege escalation path, is the affected workload in scope for a compliance framework.
4. IaC-Aware, But Not IaC-Dependent
Detection should compare actual state against the IaC-declared baseline where IaC coverage exists but it cannot be blind to resources that sit outside IaC entirely. A meaningful drift program covers 100% of the environment, not just the portion that happens to be version-controlled.
5. Actionable Remediation, Not Just Alerts
A drift finding that arrives without a clear path to resolution becomes another entry in an already-overloaded alert queue. Effective drift management needs to pair every finding with specific, executable remediation guidance, which is ideally generated in a form an engineer can act on immediately, not a CVE number and a shrug.
6. Compliance Mapping Built In
Every drift finding that represents a compliance-relevant control gap should be automatically mapped to the specific framework and control it affects (SOC 2 CC6.3, ISO 27001:2022 Control 5.18, PCI-DSS Requirement 7) so that audit evidence does not require a separate manual exercise.
The Cloudanix Approach: Continuous Drift Detection on a Unified Asset Graph
Cloudanix approaches configuration drift as a continuous monitoring problem, not a periodic audit problem. The platform connects to AWS, Azure, and GCP through an agentless, read-only integration and ingests cloud events in real time (CloudTrail, Azure Activity Logs, and GCP Audit Logs) rather than relying on scheduled scans that leave gaps between runs.
Real-Time Detection, Not Scheduled Scans
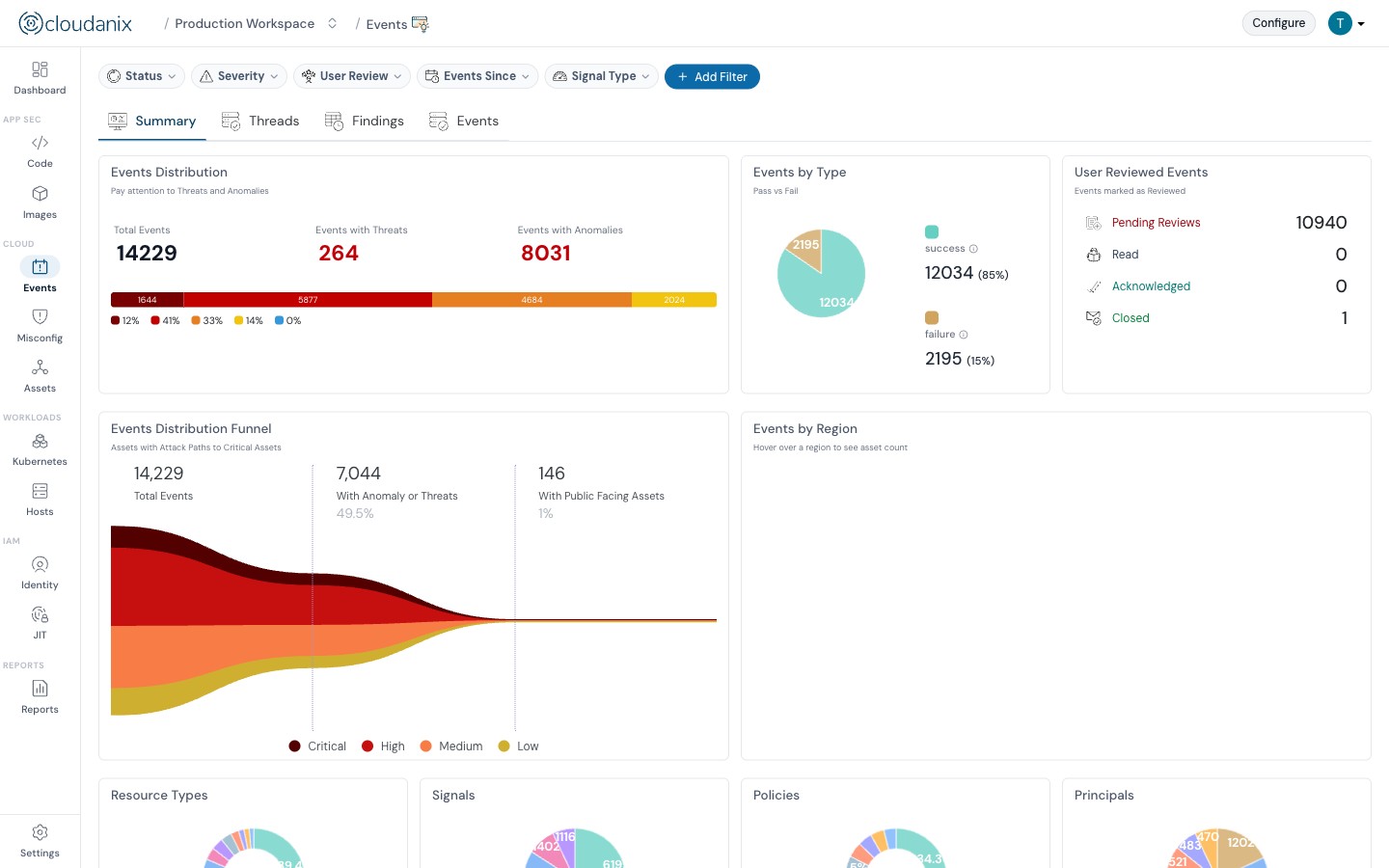
Event-driven detection surfaces configuration changes as they happen — with the identity, timestamp, and affected resource attached.
Because Cloudanix’s integration is event-driven, configuration changes are visible as they happen, not at the next scan window. A security group modified in the AWS console, an IAM policy change in GCP, a storage account permission update in Azure; each surfaces in the Cloudanix dashboard close to real time, with the specific change, the identity that made it, and the timestamp attached.
Findings With Context, Not Just a Diff
Drift findings in Cloudanix are evaluated against the unified asset graph, the same Cartography-style model that underlies the platform’s CSPM, CIEM, and CWPP capabilities. This means a drift finding does not arrive in isolation. If a newly modified security group exposes a port to the internet, Cloudanix can show whether that security group is attached to a resource with an unpatched CVE, whether the IAM role attached to that resource has excessive permissions, and whether there is a recent anomalous access pattern associated with it. The finding comes with the surrounding risk picture, not just the fact that something changed.
1,000+ Misconfiguration Rules With Cross-Cloud Parity
Cloudanix evaluates drift and configuration state against more than 1,000 rules that maintain parity across AWS, Azure, and GCP. Meaning the same underlying risk (a publicly accessible storage resource, an overly permissive role, an unencrypted volume) is detected using an equivalent rule regardless of which cloud it occurs in. For organizations running multi-cloud, this removes the need to maintain separate detection logic per cloud or accept inconsistent coverage between environments.
GenAI-Generated Remediation Playbooks
This is where it matters to be precise about what Cloudanix delivers today: the platform does not auto-remediate drift or misconfigurations on its own. What it provides instead is GenAI-generated, copy-paste-ready remediation playbooks for every finding — specific CLI commands and step-by-step guidance tailored to the exact resource and cloud provider in question, so the engineer responsible for the fix has everything they need without researching the correct remediation from scratch. The human stays in the loop and executes the fix; Cloudanix removes the research and guesswork from that process.
Cloudanix does not run automated fixes against your infrastructure without human action. Every remediation is delivered as an executable playbook that an engineer reviews and runs. Which keeps a human decision point in front of every change to production, while still collapsing the time between ‘we found this’ and ‘this is fixed’ from hours of research to minutes of copy-paste execution.
BYOR — Bring Your Own Rules
Organizations with internal policy requirements that go beyond the standard rule library can author custom drift and configuration rules via Cloudanix’s BYOR API. This matters specifically for drift management because every organization’s IaC baseline and internal standards are different. A generic rule library cannot fully capture what ‘drifted from our intended state’ means for a specific company’s specific architecture.
Compliance Mapping Without Manual Work
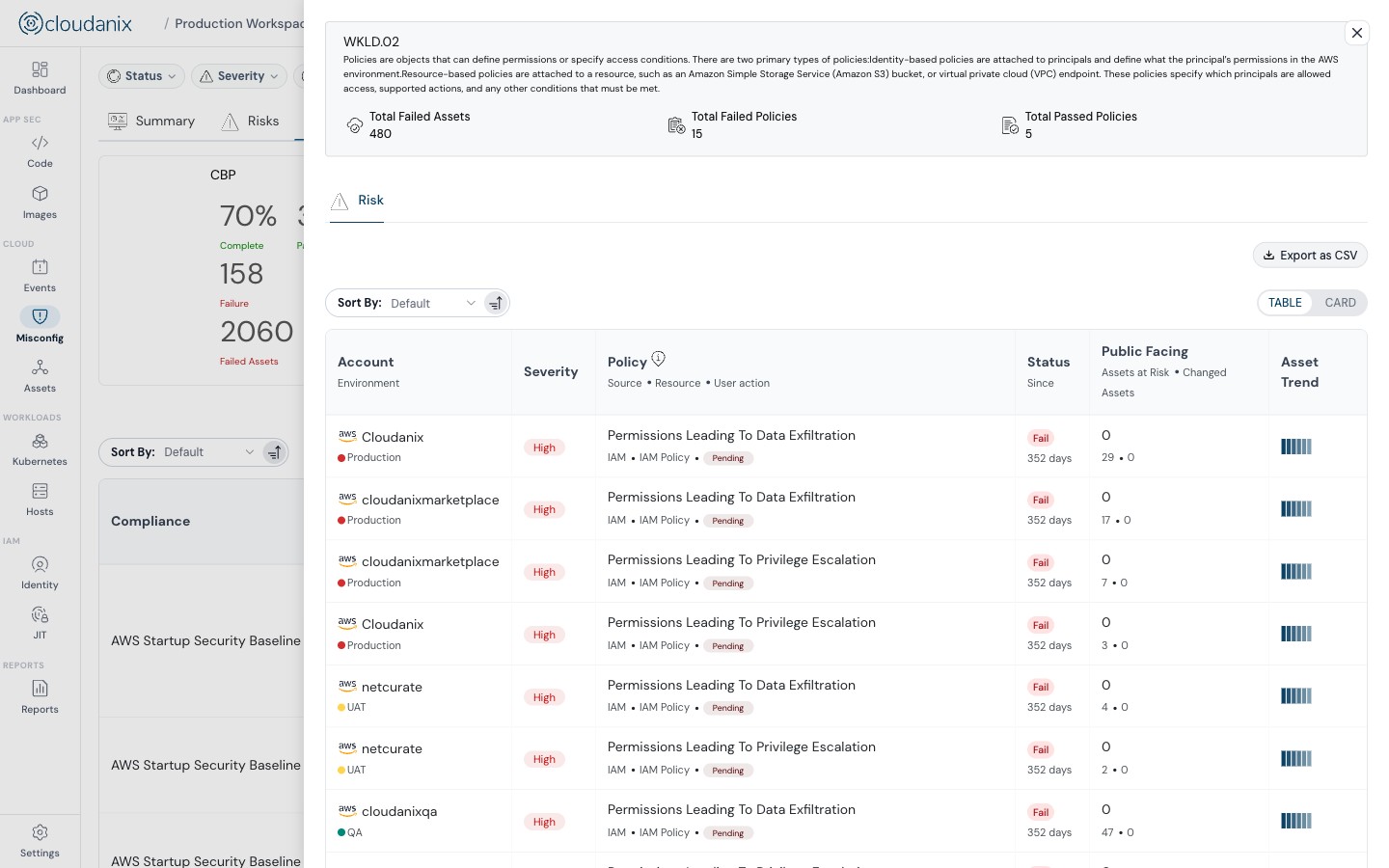
Every drift finding is automatically mapped to the specific compliance framework and control it affects — audit evidence without manual work.
Drift findings that touch a compliance-relevant control are automatically mapped to the specific framework and control affected across the 15+ frameworks Cloudanix supports, including SOC 2, ISO 27001:2022, HIPAA, PCI-DSS, NIST, FedRAMP, GDPR, and DPDPA. For an organization preparing for an audit, this means the evidence that a drift event was detected, attributed to an identity, and remediated within a defined window is available without manually reconstructing the timeline after the fact.
Customer proof point: Eversana (Healthcare, US: 80+ AWS accounts plus equivalent Azure/GCP): HIPAA audit prep reduced from weeks to hours, with unified posture visibility across business units replacing what was previously a manual, cloud-by-cloud reconciliation exercise.
Natural Language Search Across the Asset Graph
Because drift findings live on the same graph as the rest of Cloudanix’s posture and identity data, security teams can query the environment directly by asking in plain English — which resources have drifted from their IaC baseline in the last 30 days, or which drift events touched a resource with internet-facing exposure. This removes the need to manually cross-reference findings across separate dashboards to answer a question that should have a direct answer.
30-Minute Deployment
Cloudanix connects agentlessly via a read-only IAM role, with first findings (including existing drift and misconfigurations) visible the same day. There is no agent deployment required for the CSPM and drift detection layer, and no professional services engagement needed to get a baseline view of where your environment currently diverges from its intended state.
Building a Drift Management Program: A Practical Framework
For a security or platform team starting to formalize drift management, the following five-step framework provides a concrete starting point.
Step 1: Establish Your Baseline
Before you can detect drift, you need clarity on what ‘correct’ looks like. For resources under IaC management, the baseline is your version-controlled IaC. For resources outside IaC, the baseline needs to be your documented security policy and architecture standards even in the absence of a literal IaC file to compare against.
Step 2: Identify Your Coverage Gaps
Map what percentage of your cloud environment is actually under IaC management versus what exists outside it. Resources outside IaC are not exempt from drift management, they simply require a different detection approach, typically policy-based rather than state-comparison-based.
Step 3: Deploy Continuous, Cross-Cloud Detection
Move from periodic, manual, or single-cloud detection to continuous, event-driven monitoring that spans every cloud your organization operates. This is the step that converts drift management from a reactive audit exercise into an ongoing security control.
Step 4: Define Your Response SLA
Not every drift finding requires the same urgency. Establish response time expectations based on risk. A publicly exposed resource demands a same-day fix; a minor tagging inconsistency does not. Pair this with clear ownership: who is responsible for remediating drift on which resources.
Step 5: Close the Loop With Compliance Evidence
Ensure that every detected and remediated drift event generates evidence mapped to the compliance frameworks your organization operates under. This turns drift management from a purely operational practice into a documented control that strengthens your audit posture rather than merely keeping infrastructure tidy.
The Compliance Angle: Why Drift Matters to Auditors
Auditors evaluating access control, change management, and configuration management controls are increasingly asking pointed questions about how organizations detect and respond to unauthorized or unreviewed configuration changes; which is precisely what drift represents when it occurs outside an approved change process.
SOC 2 (Change Management and CC6 Controls)
SOC 2 audits assess whether changes to production systems follow an approved process and whether deviations are detected and addressed. A drift event (a change made outside the approved IaC pipeline) is exactly the kind of deviation these controls are designed to catch. Evidence of continuous drift monitoring directly supports this control area.
ISO 27001:2022 Control 8.32 (Change Management)
The 2022 update to ISO 27001 includes specific change management controls requiring that changes to information processing facilities are controlled, and that unauthorized changes are identified. Continuous drift detection provides the operational evidence that this control is functioning, rather than existing only as a documented policy.
PCI-DSS v4.0 (Requirement 1 and Requirement 11)
PCI-DSS requires that network security controls are reviewed and confirmed to remain correctly configured, and that significant changes are tested before deployment. Drift detection that catches a configuration change outside of the controlled deployment process is a direct operational control supporting these requirements.
What Auditors Increasingly Expect
A documented change management policy is not sufficient evidence on its own. Auditors want to see that deviations from approved configuration are actually being detected in practice, and that requires continuous monitoring, not a policy document describing intent.
Conclusion
Configuration drift is not a problem you solve once. It is a continuous condition of operating cloud infrastructure at any meaningful scale, with any meaningful number of people and systems touching it. The organizations that manage it well are not the ones that prevent every single manual change or emergency fix. That is neither realistic nor always the right call under pressure. They are the ones that have continuous visibility into when drift occurs, clear context on what risk it introduces, and a fast, reliable path from detection to remediation.
The gap between your IaC-defined environment and your actual running environment will never close to zero. What matters is whether that gap is visible, monitored, and acted on quickly; or whether it is silently widening until an incident, an audit finding, or a breach makes it visible the hard way.
See your drift picture in 30 minutes. Cloudanix connects agentlessly with a read-only IAM role and surfaces your configuration drift, misconfigurations, and policy violations the same day — across AWS, Azure, and GCP, with copy-paste-ready remediation playbooks for every finding. Get started →
Related Resources
- Top 15 Cloud Misconfigurations in 2026 and How to Fix Them
- CSPM Tools Compared: What to Look for in 2026
- How to Use CSPM to Detect and Remediate Cloud Misconfigurations
- Why Do We Need Continuous Audits for Public Cloud
- The 2026 CNAPP Compliance Framework: Turning Audit from Crisis to Continuity
- Understanding Infrastructure as Code (IaC) Security
- A Complete List of AWS IAM Misconfigurations
- Cloud Asset Management: Complete 2026 Guide for Multi-Cloud Teams
- What is CSPM? Cloud Security Posture Management